Reactive Programming과 Functional Reactive Programming 의 개념을 알아보자
Reactive Programming
Wikipedia는 역시 너무 어렵다.
a declarative programming paradigm concerned with data streams and the propagation of change.
// 데이터의 순서와 변경과 관련된 선언적 프로그래밍 패러다임
더 직관적인 뜻을 찾아보자.
Reactive programming is programming with asynchronous data streams.
// 비동기 데이터 흐름을 다루는 프로그래밍
// 출처: https://gist.github.com/staltz/868e7e9bc2a7b8c1f754
글만 보면 막연하니, 그림을 보자.
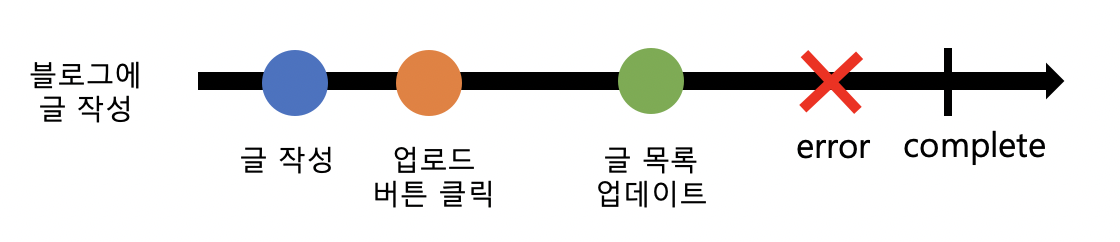
블로그에 글을 작성하는 상황을 예를 들어서 생각해보자,
Data stream이란 시간의 흐름에 따라 진행되는 이벤트의 sequence를 말한다.
조금 쉽게 생각하면, 연속된 데이터의 처리/operation라고 할 수 있다.
블로그에 글을 작성하는 경우에는, 위의 순서로 이벤트가 발생한다 / 데이터가 처리된다.
reactive programming은 비동기 이벤트 흐름을 다루며, 이름 그대로 빠르게 반응하는 것을 목표로 한다.
빠르게 반응하기 위해서는 이벤트가 발생하는지 관찰하고(observe) 값이 변할 때마다 새로 연산을 수행해아한다.
이렇게, 객체 A에 변화가 생기면 객체 A를 관찰하는 observer들에게 변화를 통지하는 패턴을 observation design pattern이라고 한다.
비동기 이벤트를 처리하는 reactive programming은 observation design pattern을 기본으로 한다.
이벤트 하나가 완료되면, value / error / complete signal 중 하나가 발생한다.
observer는 발생값(value/error/complete signal)에 따라 다른 함수(handler)를 실행한다.
이벤트의 처리 신호를 듣는다(listen)고도 표현하며 처리 신호를 observer에게 보내는 것을 subscribe라고도 한다.
Functional Reactive Programming
Functional Reactive Programming은 Reactive Programming을 functional programming을 이용해서 구현한 것이다.
functional programming이란, 수학적 의미의 함수의 역할이 강조된 프로그래밍 기법이다.
수학적 의미에서의 함수란, input을 넣으면 output이 나오는 box로 생각할 수 있다.

Functional programming에서는 mutuable variable, assignment, loops를 지양하며, input -> output의 관계에 집중한다.
예를 들면, imperative programming에서는 흔히, 아래처럼 함수를 작성하지만,
def add(a:Int):Int = a + 3
functional programming에서는 state를 갖는 것을 피하고, 숨겨진 input과 output을 없도록 하기 위해서 아래처럼 작성한다.
def add(a:Int, b:Int) = a+b여기서 숨겨진 input과 숨겨진 output을 각각 side-cause, side-effect라고 한다.
이것들이 많아지면 코드를 변경할 때 예상하지 못한 결과가 나올 수 있고,
코드를 변경할 때 모든 함수의 내부를 확인하면서 디버깅을 해야하는 어려움이 있다.
functional reactive programming은 결국 side effect를 줄이면서 reactive programming을 구현하는 방법인 것이다!
구체적인 구현 코드는 다음 글에서 알아보자
4 Reactive principles
Reactive programming은 4가지의 principle을 갖는다.
1) responsive : 빠르게 반응한다. reactive programming의 방법이기도 하다.
2) resilient : 어떤 상황에서도 responsive하게 동작하도록 한다.
3) scalable : load에 따라 responsive할 수 있도록 시스템을 업그레이드할 수 있다.
4) message driven : reactive programming을 구현하는 방법이다.
event-driven, actor-based, event-driven + actor-based가 있다.
event-driven : observer가 event를 관찰한다.
actor-based : message가 actor에게 직접 전달된다.
참고:
https://brunch.co.kr/@oemilk/79
https://m.blog.naver.com/jdub7138/220983291803#
https://gist.github.com/staltz/868e7e9bc2a7b8c1f754
https://blog.redelastic.com/what-is-reactive-programming-bc9fa7f4a7fc
'언어 > Scala' 카테고리의 다른 글
| Scala abstract class vs. trait, singleton, case class (0) | 2020.02.13 |
|---|---|
| Scala class, constructor(생성자), new, instance (0) | 2020.02.13 |
| for {...} yield 실험 결과 정리 (0) | 2020.02.03 |
| scala for comprehension, for {...} yield (0) | 2020.02.03 |
| type / class 확인하기 (0) | 2020.01.26 |